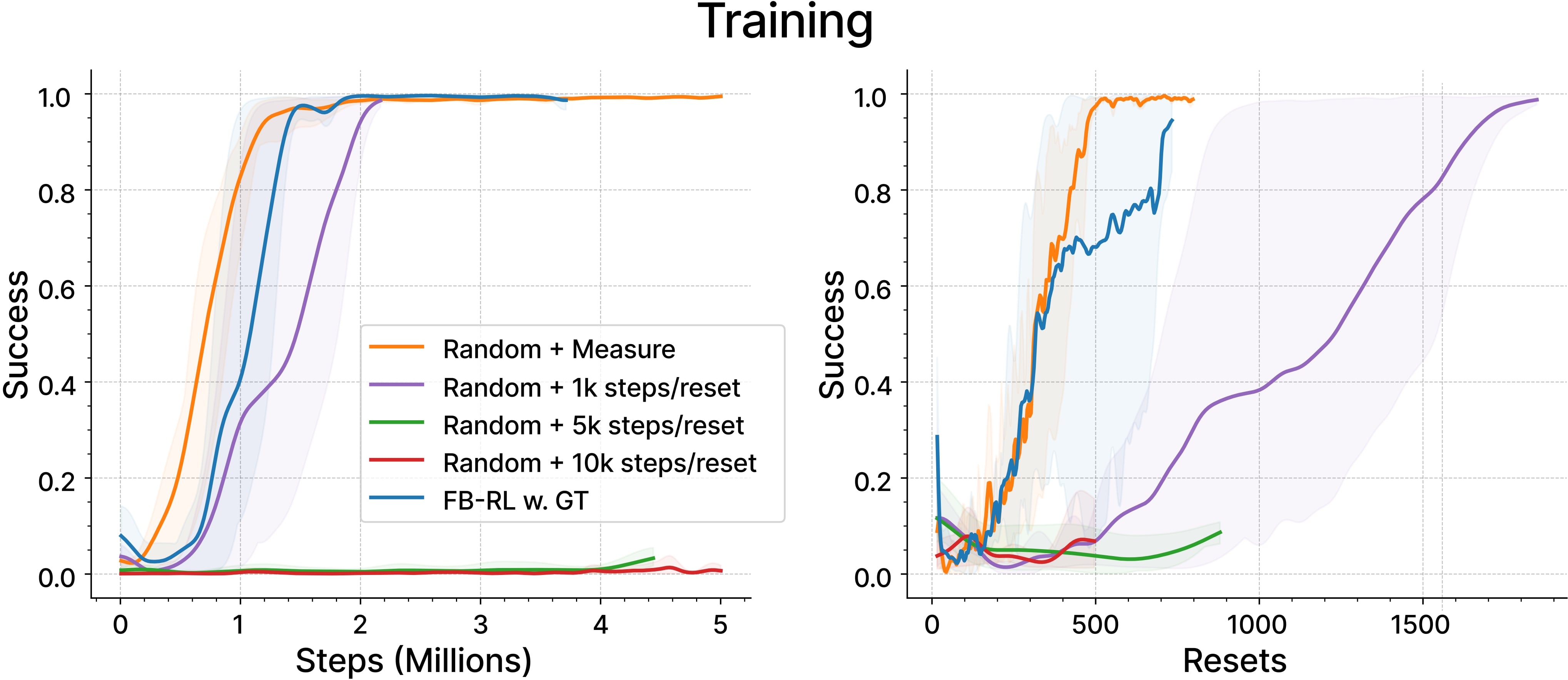
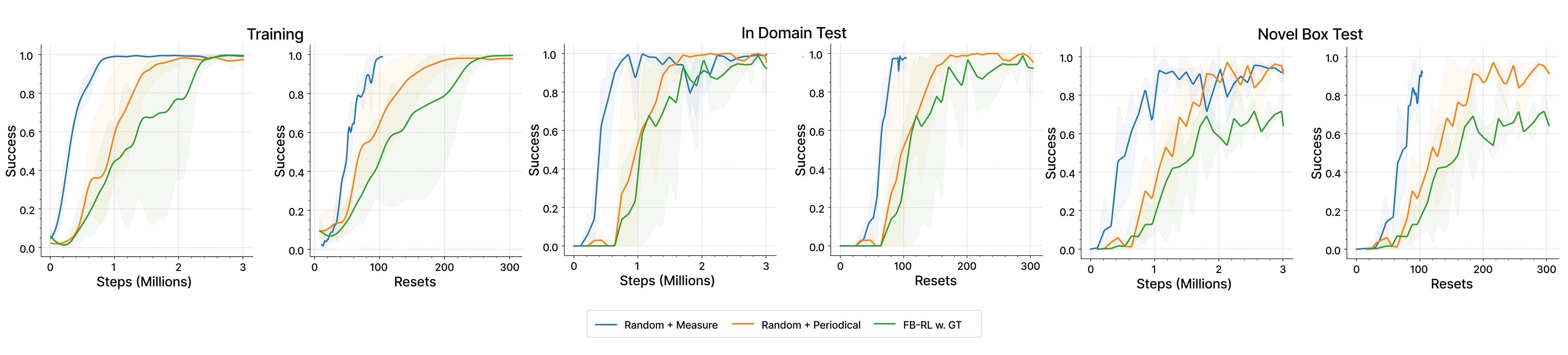
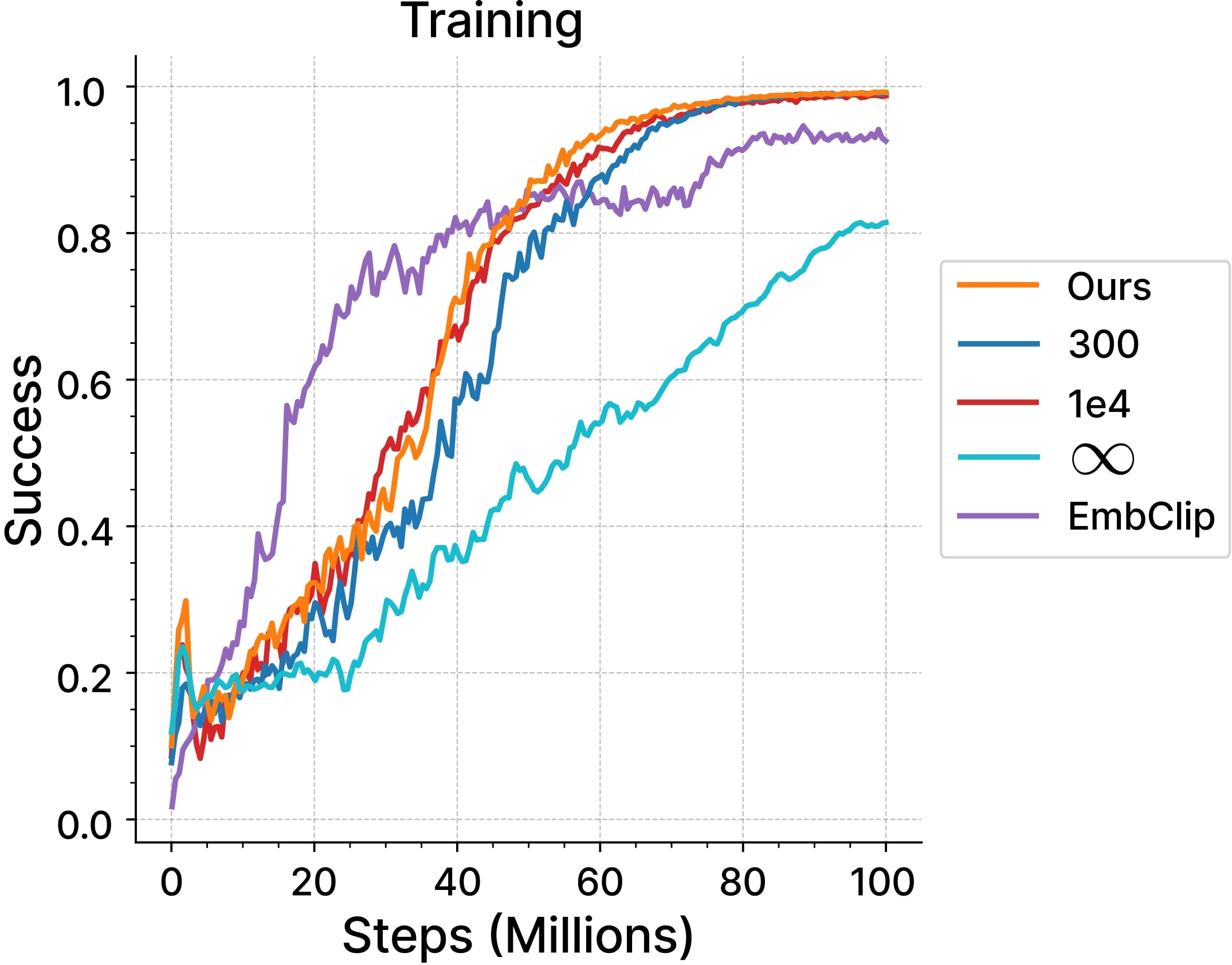
Methods
Two fundamental problems when attempting to build generalizable agents in the reset-free setting
are irreversible transitions and limited state diversity. As it is often impractical or impossible
to guarantee that an agent does not undergo any irreversible transitions during training, we
present measures that we use to quantify when an agent has
undergone such a transition. Next, we take a
first step towards building generalizable RM-RL agents; in particular, we propose to do away with
the learned forward-backward policies popular in prior RF-RF work and, instead, learn a single
policy which is presented with randomly generated goals during training.
Existence of Near Irreversible States
Some irreversible transitions are explicit, e.g. a glass is dropped and shatters.
However, in a more complex real-world environment, they may be more subtle. For instance,
when a robot is tasked with cleaning a room, it may encounter situations where some
trash is accidentally pushed or blown into hard-to-reach locations, such as under a sofa or
in the corners of the room. In such cases, the robot may find it challenging, but not strictly
impossible, to pick up or sweep debris back using its regular cleaning tools. We refer to these
states that are difficult, but not impossible, to recover from as near-irreversible (NI) states.
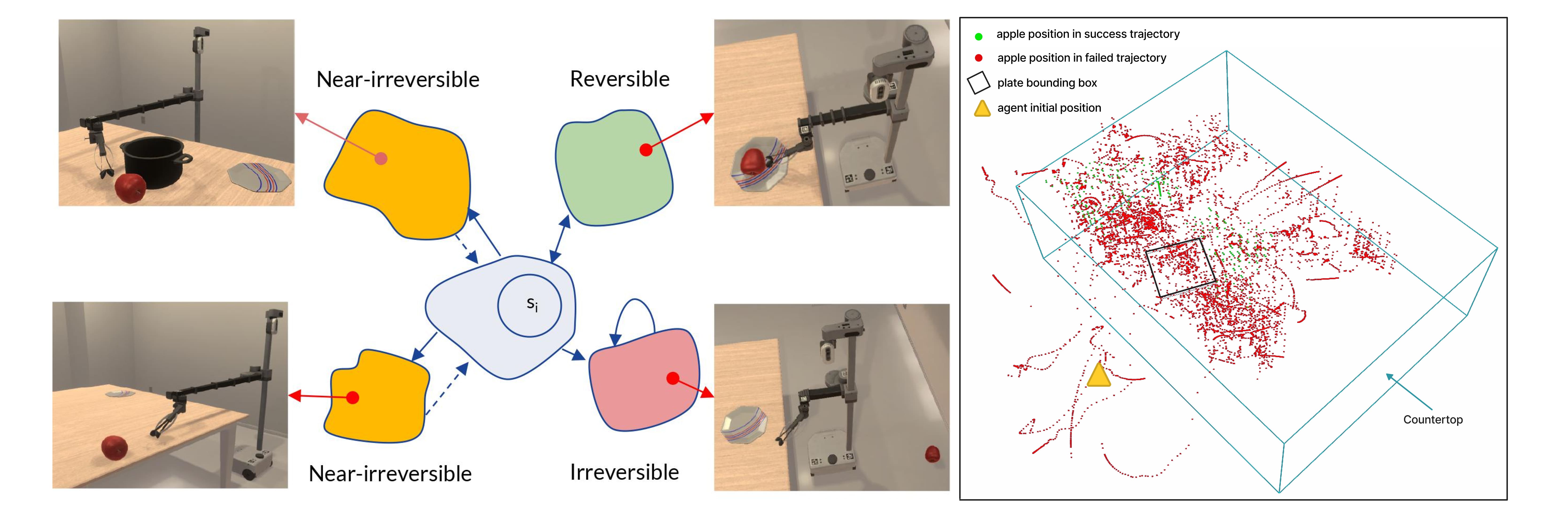 Reversible and (Near) Irreversible States in Stretch-P&P.
Left: Reversible (top right): the target apple is within easy reaching distance.
Irreversible (bottom right): the apple has fallen off the table, as the agent cannot rotate
in Stretch-P&P the apple can no longer be reached. Near-irreversible (left):
the apple is in tricky-to-reach locations being behind other objects or at the extreme
limits of the arm's reaching capabilities.
Right: Visualizing successful and failed object trajectories in Stretch-P&P during training. Notice that
the object occupies many diverse states and can fall off of the table or roll away from the agent.
Reversible and (Near) Irreversible States in Stretch-P&P.
Left: Reversible (top right): the target apple is within easy reaching distance.
Irreversible (bottom right): the apple has fallen off the table, as the agent cannot rotate
in Stretch-P&P the apple can no longer be reached. Near-irreversible (left):
the apple is in tricky-to-reach locations being behind other objects or at the extreme
limits of the arm's reaching capabilities.
Right: Visualizing successful and failed object trajectories in Stretch-P&P during training. Notice that
the object occupies many diverse states and can fall off of the table or roll away from the agent.
 Reversible and (Near) Irreversible States in Sawyer Peg.
Point cloud visualizations for evaluations on the narrower and the normal-sized table,
where red points indicate the object (peg) head positions for failed trajectories while greens
show the successful ones. Evaluations on two settings have the exact the same performance and
rollouts trajectories for the final checkpoint (last two figures), but the same policy is leading
to different consequences for the evaluation at 300k steps (first two figures):
the peg always drops off the narrower table but mostly is still on the edge of the normal-size table.
Reversible and (Near) Irreversible States in Sawyer Peg.
Point cloud visualizations for evaluations on the narrower and the normal-sized table,
where red points indicate the object (peg) head positions for failed trajectories while greens
show the successful ones. Evaluations on two settings have the exact the same performance and
rollouts trajectories for the final checkpoint (last two figures), but the same policy is leading
to different consequences for the evaluation at 300k steps (first two figures):
the peg always drops off the narrower table but mostly is still on the edge of the normal-size table.
Measures of Irreversibility
Suppose that agent has taken $t$ steps producing the trajectory $\mathcal{T}_{t}=\{\tau_\pi(0), \ldots, \tau_\pi(t)\}$.
Intuitively, undergoing an NI transition should correspond to a decrease in the degrees of freedom available
to the agent to manipulate its environment: that is, if an agent underwent an NI transition at timestep $i$ then
the diversity of states $\tau_{\pi}(i+1),\ldots, \tau_{\pi}(t)$ should be small compared to the diversity before
undergoing the irreversible transition. Further, the set of near-irreversible states also depends on the agent's
policy $\pi$: which states should be considered near-irreversible can, and should, change during training.
To formalize this, we can compute the above count, which we call $\phi_{W,\alpha,d,}(\mathcal{T}_t)$, as
\[
\max_{(i_0, \ldots, i_m)\in P(t)}\sum_{j=0}^{m-1}1_{[i_{j+1}-i_{j} \geq N]}
\cdot 1_{\{ d\left(\tau_\pi(i_j), \ldots, \tau_\pi(i_{j+1}-1)\right) < \alpha\}}
\]
where $d:\mathcal{S}^H\to \mathbb{R}_{\geq0}$ is some non-negative measure of diversity among states.
As $\phi_{W,\alpha,d}$ is a counting function, we can turn it into a decision function simply by
picking some count $N>0$ and deciding to reset when $\phi_{W,\alpha,d}\geq N$. In particular,
we will let $\Phi_{W,N,\alpha,d}$ be the function that equals 1 if and only if $\phi_{W,\alpha,d}\geq N$.
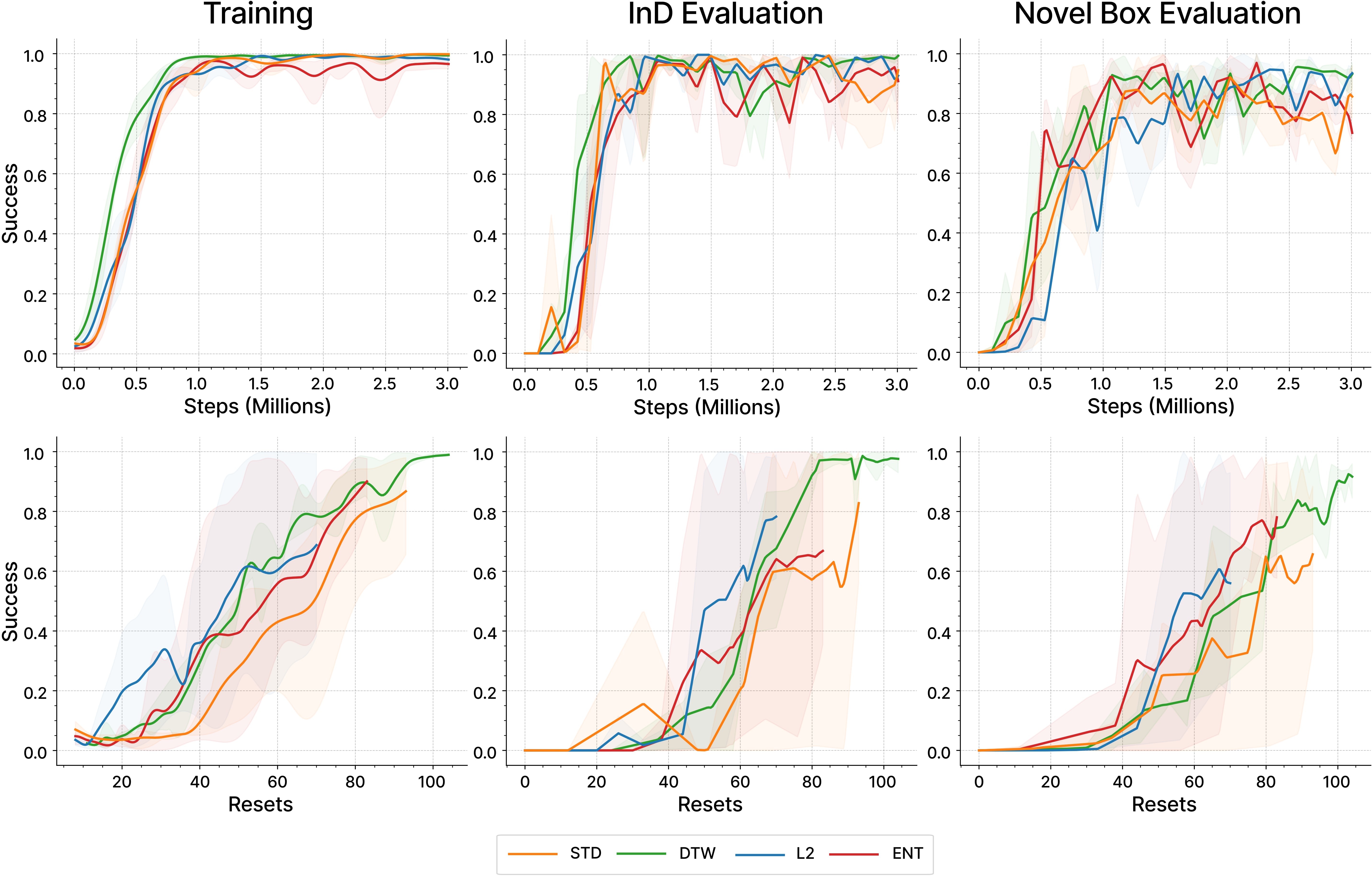
In our experiments we evaluate several diversity measures $d(s_1,\ldots, s_H)$ including:
(1) a dispersion-based method using an empirical measure of entropy, or the mean standard deviation of the $s_i$,
(2) a distance-based method using euclidean distance, or dynamic time warping (DTW).
While we find surprisingly robust performance when varying $d$, we expect that there is no single best choice of diversity measure for all tasks.
See our paper for more details.
RM-RF with a Single Policy
We aim to use single policy to achieve RM-RL that can adapt to general
embodied tasks. Recall the objective for goal-conditioned POMDP in traditional episodic RL:
\[\pi^\star \arg\max_\pi J(\pi\mid g) = \arg\max_\pi \mathbb{E}\left[\sum_{t=0} ^ \infty \gamma^t r(s_t, a_t\mid g)\right]\]
In FB-RL, the ``forward'' goal space is normally defined as a singleton
$\mathcal{G}_{f} = \{g^\star\}$ for the target task goal $g^\star$ (e.g. the apple is on the plate,
the peg is inserted into the hole, \etc). The goal space for ``backward'' phase is then the (generally limited)
initial state space $\mathcal{G}_{b} = \mathcal{I} \subset \mathcal{S}$ such that $\mathcal{G}_f\cap \mathcal{G}_b=\emptyset$.
As the goal spaces in FB-RL are disjoint and asymmetric, it is standard for separate forward/backward
policies (with separate parameters) and even different learning objectives to be used when training
FB-RL agents. In our setting, however, there is only a single goal space which, in principle, equals
the entire state space excluding the states we detect as being NI
(\ie, $\mathcal{G} = \mathcal{S} \setminus \{s_t\mid s_t\in\tau_{\pi} (t) \in \mathcal{T}_\pi, \Phi_{W,N,\alpha,d} (\mathcal{T}_\pi) = 1\}$).
In our training setting, we call each period between goal switches a \textit{phase} and, when
formulating our learning objectives, treat these phases as separate "episodes" in episodic approaches.
In our RM-RL setting, we aim for evaluating both the sample efficiency and intervention
efficiency such that an agent or algorithm is considered as parfait with less training steps and human supervisions,
i.e. minimize both:
\[
\sum_{t=0}^\infty J(\pi^\star) - J(\pi^\pi_t), \sum_{k=0}^\infty J(\pi^\star) - J(\pi^\pi_k)
\]
where $\pi_t, \pi_k$ are the policy learned after $t$ steps and $k$ interventions respectively, while also with meaningful generalizations.
 Episodic, Reset-Free, and Reset-Minimizing RL.
In standard (i.e. episodic) reinforcement learning (RL) agents have their environments reset
after every success or failure, an expensive operation in the real world. In Reset-Free RL
(RF-RL), researchers have designed "reset games" which allow for learning so long as special
care is taken to avoid irreversible transitions (e.g. an apple falling out of reach). We
consider Reset-Minimizing RL (RM-RL) where in realistic and dynamic environments agents may
request human interventions but should minimize these requests.
Episodic, Reset-Free, and Reset-Minimizing RL.
In standard (i.e. episodic) reinforcement learning (RL) agents have their environments reset
after every success or failure, an expensive operation in the real world. In Reset-Free RL
(RF-RL), researchers have designed "reset games" which allow for learning so long as special
care is taken to avoid irreversible transitions (e.g. an apple falling out of reach). We
consider Reset-Minimizing RL (RM-RL) where in realistic and dynamic environments agents may
request human interventions but should minimize these requests.